MySQL分区可行性调研
版权归原作者所有。 本文最后更新于:2023年9月27日 晚上
MySQL分区可行性调研
一、什么是分区
1、MySQL存储原理
MySQL是支持ACID事务的,其中一个D就是持久化,持久化就代表了:插入MySQL的数据最终还是要落到磁盘中,这样才能做到真正的持久化。
MySQL存储文件在磁盘中,每一个数据库里面有很多存储文件:
针对InnoDB引擎来说
数据库配置信息文件(.opt)
表元数据文件(.frm)、表数据文件(ibd);
.opt文件
包含数据库配置信息的文件。
.frm 文件
包含元数据的文件,例如 MySQL 表的表定义。
对于备份,您必须始终将完整的.frm文件集与备份数据一起保留 ,以便能够恢复备份后更改或删除的表。
尽管每个InnoDB表都有一个 .frm文件,InnoDB 但在系统表空间中维护自己的表元数据 。
.ibd文件
保存了数据库的数据信息和关联索引信息。
file-per-table 表空间和通用表空间 的数据文件 。File-per-table 表空间 .ibd文件包含单个表和关联的索引数据。通用表空间 .ibd文件可能包含多个表的表和索引数据。MySQL 5.7.6 中引入了通用表空间。
该.ibd文件的扩展名不适用于 系统表空间,它由一个或多个ibdata文件。
如果使用该DATA DIRECTORY =子句创建 file-per-table 表空间或通用表空间,则该 .ibd文件位于指定路径,在正常数据目录之外,并由.isl 文件指向 。
2、MySQL分区原理
官方详细文档:https://dev.mysql.com/doc/refman/5.7/en/partitioning.html
从 MySQL 5.7.17 开始,MySQL 服务器中的通用分区处理程序已弃用,并在 MySQL 8.0 中删除,因为用于给定表的存储引擎预计会提供自己的(“本机”)分区处理程序。目前,只有InnoDB和 NDB存储引擎可以做到这一点。
要准备迁移到 MySQL 8.0,任何具有非本机分区的表都应更改为使用提供本机分区的引擎,或者设为非分区。例如,要将表更改为InnoDB,请执行以下语句:
ALTER TABLE table_name ENGINE = INNODB;设置分区之后会在磁盘中产生用#分隔开的独立的分区文件
还有独立一个文件为pre的分区信息表,类似磁盘分区的一个mbr分区文件
分区键的数据类型。 分区键必须是整数列或解析为整数的表达式。ENUM不能使用使用列的表达式 。列或表达式值也可能是NULL.
最大分区数。 不使用NDB存储引擎的给定表的最大可能分区数是 8192。这个数字包括子分区。
2.1、分区类型
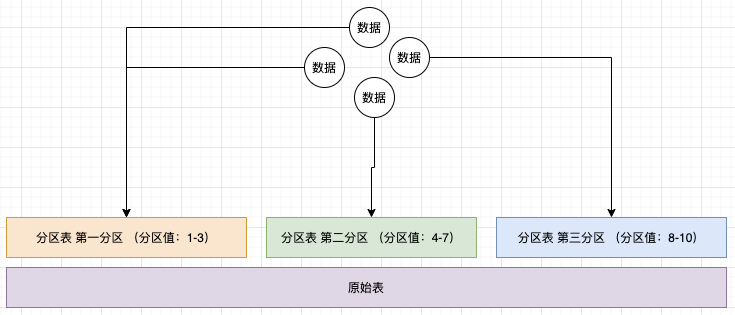
2.1.1、 范围划分
分段划分: 1-10 11-20 数据落在哪个区间,则在哪个分区中。 (是一组连续的区间)
分区值为固定值
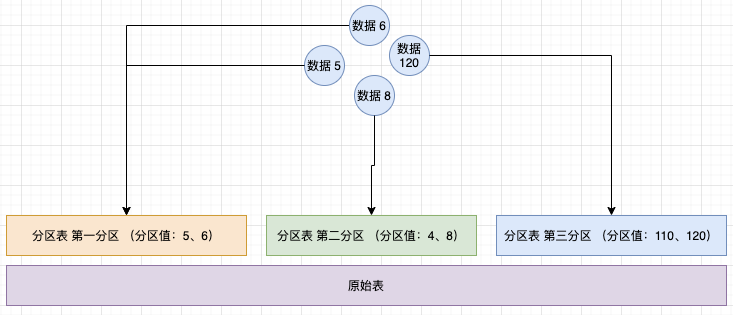
2.1.2、 LIST 分区
类似于分区 by RANGE,不同之处在于分区是根据几个离散的值,例如 5 、6 、8 、9是一个分区
分区值为固定值
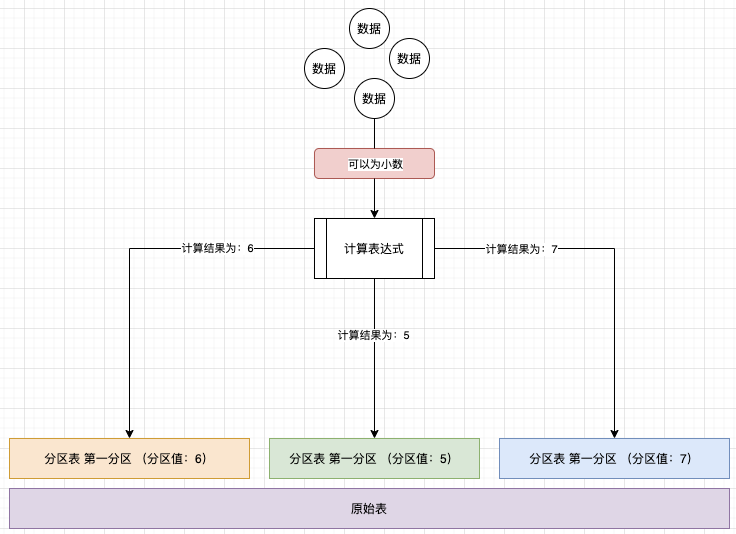
2.1.4、列分区
所有整数类型:TINYINT、 SMALLINT、 MEDIUMINT、 INT ( INTEGER) 和 BIGINT。
DATE和 DATETIME。
下面的字符串类型: CHAR, VARCHAR, BINARY,和 VARBINARY。
分区值设置为列名,根据选择列对应的数据进行分区,例如时间分区
2.1.4.1、RANGE COLUMNS分区RANGE在以下方面与分区有很大不同
① 不接受表达式,只接受列名。
② 接受一列或多列的列表。
③ 分区基于 元组(列值列表)之间的比较,而不是标量值之间的比较。
⑤ 分区列不限于整数列;字符串, DATE并且 DATETIME列也可以作为分区列。
CREATE TABLE table_namePARTITION BY RANGE COLUMNS(column_list) ( PARTITION partition_name VALUES LESS THAN (value_list)[, PARTITION partition_name VALUES LESS THAN (value_list)][, ...])2.1.4.2、RANGE COLUMNS分区RANGE在以下方面与分区有很大不同
CREATE TABLE customers_1 ( first_name VARCHAR(25), last_name VARCHAR(25), street_1 VARCHAR(30), street_2 VARCHAR(30), city VARCHAR(15), renewal DATE)PARTITION BY LIST COLUMNS(city) ( PARTITION pRegion_1 VALUES IN('Oskarshamn', 'Högsby', 'Mönsterås'), PARTITION pRegion_2 VALUES IN('Vimmerby', 'Hultsfred', 'Västervik'), PARTITION pRegion_3 VALUES IN('Nässjö', 'Eksjö', 'Vetlanda'), PARTITION pRegion_4 VALUES IN('Uppvidinge', 'Alvesta', 'Växjo'));2.1.5、 HASH 分区
使用这种类型的分区,根据用户定义的表达式返回的值选择分区,该表达式对要插入表的行中的列值进行操作。该函数可以由任何在 MySQL 中有效的表达式组成,该表达式产生一个非负整数值。LINEAR HASH也可以使用此类型的扩展名。

2.1.6、 KEY分区
这种类型的分区类似于分区 by HASH,只是只提供了一个或多个要评估的列,并且 MySQL 服务器提供了自己的散列函数。这些列可以包含非整数值,因为 MySQL 提供的散列函数保证整数结果,而不管列数据类型如何。LINEAR KEY也可以使用此类型的扩展名 。
数据库分区的一个非常常见的用途是按日期分隔数据。一些数据库系统支持显式日期分区,MySQL 在 5.7 中没有实现。但是,在 MySQL 中创建基于DATE、 TIME、 或 DATETIME列或基于使用这些列的表达式的分区方案并不困难 。
按KEY或分区时LINEAR KEY,可以使用DATE、 TIME、 或 DATETIME列作为分区列,而无需对列值进行任何修改。
2.1.7、 子分区
类似嵌套分区,每一个分区下面再加一个分区
2.7 MySQL 分区如何处理 NULL
NULL会被认为比任何值都小的分区里面放置
具体详细使用方式为:https://dev.mysql.com/doc/refman/5.7/en/partitioning-handling-nulls.html
二、分区与分表的区别
分表:分表是从物理上分开,一张表分为多张表
分区:分区是从逻辑上分开,一张表还是一张表,只是里面按照固定字段或者设定值来进行分不同的存储区
三、分区的优点
1、分区之后,查询只查询单个区,或者几个区,查询数据量总体减少,提高查询性能
2、分区在逻辑上进行拆分表数据,实际上还是同一张表
3、分区可以设置多个磁盘进行分区存储,比单个磁盘分区容量更大
4、插入数据不需要手动的去处理插入哪个表的问题,增删改不需要修改
5、不需要引入第三方中间件,有效降低开发难度
官方给出优点:
分区使得在一个表中存储的数据比单个磁盘或文件系统分区上存储的数据更多成为可能。
通过删除仅包含该数据的分区(或多个分区),通常可以轻松地从分区表中删除失去其用处的数据。相反,在某些情况下,通过添加一个或多个新分区来专门存储该数据,可以极大地促进添加新数据的过程。
某些查询可以极大地优化,因为满足给定WHERE子句的数据只能存储在一个或多个分区上,这会自动从搜索中排除任何剩余的分区。由于在创建分区表后可以更改分区,因此您可以重新组织数据以增强在首次设置分区方案时可能不经常使用的频繁查询。这种排除不匹配分区(以及它们包含的任何行)的能力通常称为 分区修剪。
出处:https://dev.mysql.com/doc/refman/5.7/en/partitioning-overview.html
四、分区的缺点
1、表可访问性。 有时,服务器 SQL 模式的更改可能会使分区表无法使用。
2、分区可能在MySQL版本上会有所差异,该问题不可控。
3、存储引擎。 使用表进行分区操作、查询和更新操作通常MyISAM 比使用InnoDB或 NDB表更快。(对于有事务的表不太适合分区)
4、全文索引。 分区表不支持FULLTEXT 索引或搜索,即使是使用InnoDB或 MyISAM存储引擎的分区表 。
5、临时表。 临时表不能分区。
6、InnoDB外键和 MySQL 分区不兼容。分区 InnoDB表不能有外键引用,也不能有外键引用的列。InnoDB具有或被外键引用的表不能被分区。InnoDB不支持将多个磁盘用于子分区。(目前仅支持此功能 MyISAM。)
6.1、InnoDB使用用户定义分区 的表的定义不得包含外键引用;不能InnoDB对定义包含外键引用的表进行分区。
6.2、任何InnoDB表定义都不能包含对用户分区表的外键引用;任何 InnoDB具有用户定义分区的表都不能包含由外键引用的列。7、不支持查询缓存。 分区表不支持查询缓存,并且对于涉及分区表的查询会自动禁用。无法为此类查询启用查询缓存。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明蚁点博客出处!